AI Crawler Statistics in 2026: What AI Crawlers Actually Want?
Live Cloudflare Radar data (June 2026): 52% of AI crawler traffic hunts training data, and shopping sites get crawled most — what AI bots want from your site.
Published •21 min read

I ran Google's Search crawling and indexing systems for five years before joining TechnologyChecker, and the shift in the last year is the sharpest I've seen. The old question was "is Googlebot reaching my pages?" The new one is "what is every AI bot taking from them, and what do I get back?" The data below answers that. Where it touches who runs these bots or how to block them, I point you to the sibling reports that cover each in depth.
What is an AI crawler?
An AI crawler is an automated bot that fetches web pages to feed artificial intelligence systems. It does so mostly to collect training data for large language models, and increasingly to fetch live pages that AI answer engines cite. Named examples include OpenAI's GPTBot, Anthropic's ClaudeBot, and PerplexityBot. The difference from a traditional search bot like Googlebot is the goal, not the mechanism.
Googlebot crawls to build a search index that sends a human visitor back to your page. An AI crawler usually has no such return trip. A training crawler reads your page, extracts what it needs into a model, and moves on. Your content shapes the model's future answers, but the reader who benefits never sees your URL or your ad. That economic gap, which I'll come back to, is why AI crawler traffic now worries site owners who never gave Googlebot a second thought.
Cloudflare separates these bots by declared purpose, and that classification is what makes the rest of this report possible. You can read the full criteria in Cloudflare's verified-bots documentation.
What AI crawlers actually want, by declared purpose

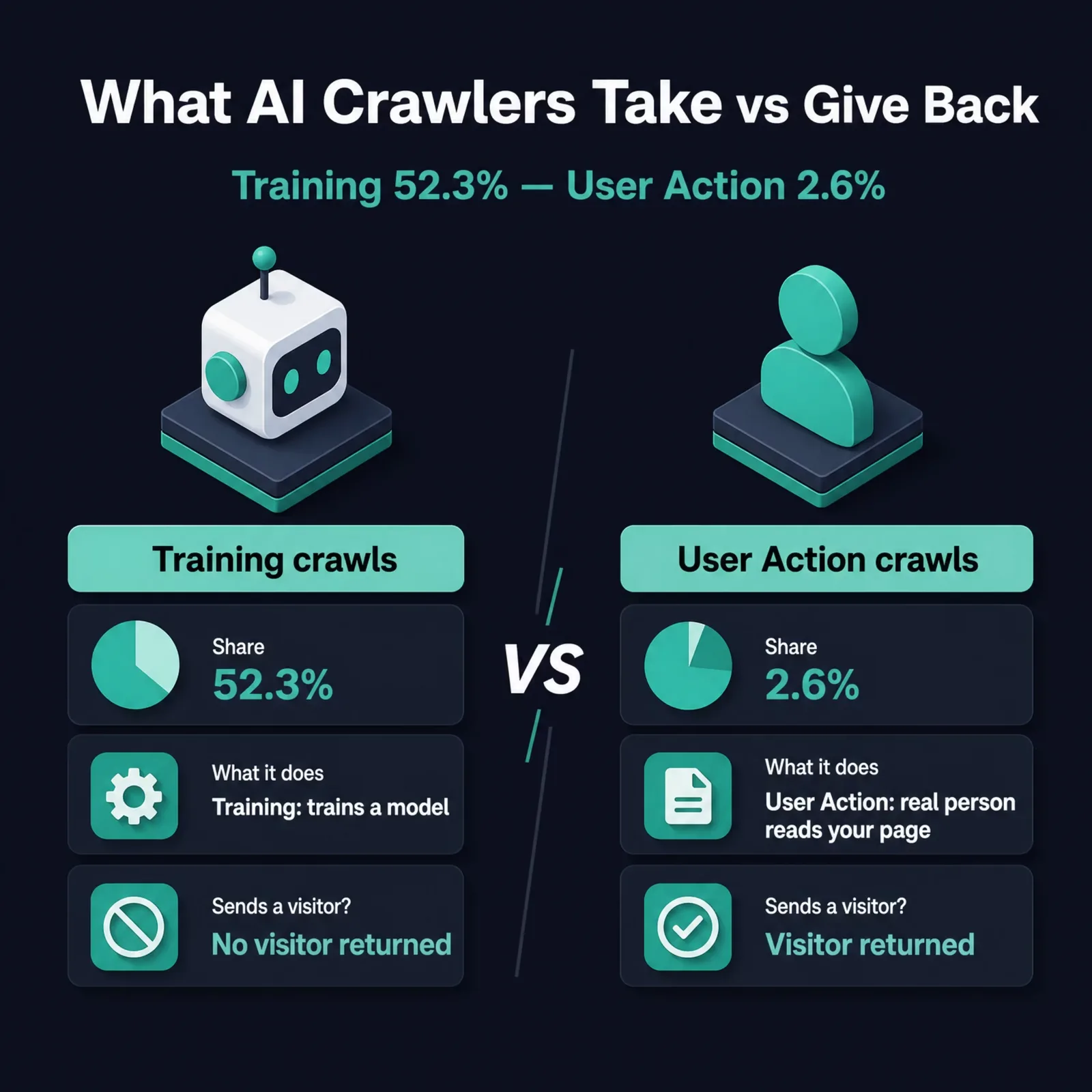
AI crawlers want training data first and everything else a distant second. Across Cloudflare's network in the 28 days to June 22, 2026, training crawls made up 52.3% of AI crawler requests, more than the next two purposes combined. Real-time fetches triggered by an actual person account for just 2.6%. The overwhelming majority of what hits your server is bulk collection that never sends a human back.
Here's the full split, straight from Cloudflare Radar:
| Crawl purpose | Share of AI crawler requests | What it means |
|---|---|---|
| Training | 52.3% | Collecting data to train or fine-tune AI models (bulk and indiscriminate) |
| Mixed Purpose | 34.2% | One crawler the operator uses for several purposes at once |
| Search | 10.1% | Building a search index, or fetching live pages to cite in AI answer engines |
| User Action | 2.6% | A real-time fetch triggered by an end user (someone pastes a URL or asks an assistant to read a page) |
| Undeclared | 0.8% | Purpose the operator hasn't declared |
The definitions matter because they change what each crawl is worth to you. A training crawl takes your content into a model with no link back. A search crawl can put your page in front of someone asking a question right now. A User Action fetch means a real person wanted your specific page in that moment, the rarest and most valuable visit of the five. Reading the table as one undifferentiated wave of "AI traffic" hides the only distinction that should drive your policy.
That table is the most recent 28-day snapshot. Average across the whole first half of 2026 instead, and the split is training 48.5%, mixed purpose 40.2%, search 8.5%, User Action 2.3%, and undeclared 0.5%. The two windows differ for a reason worth understanding: training's share was climbing all year, so the year-to-date average sits below where the number is today. The full 2026 trajectory, not just the latest snapshot, is the next section.
This report covers what AI bots want and which sites they hit. It deliberately does not rank the operators behind them. For the breakdown of which companies run the most bot traffic, see our companion report on who operates the most bot traffic.
Training is 52% of AI crawl traffic, and still climbing

Training already dominates AI crawl traffic, and it's still climbing. Across the first half of 2026, the training share of AI crawler requests rose from 41.1% to 53.3% in Cloudflare's weekly data, a 12-point gain in six months. The bigger shift underneath that number: mixed-purpose crawling, which was actually the single largest purpose back in January at 48.7%, collapsed to 33.0% as operators split their do-everything bots into clearer single-purpose ones. Training is the bot that inherited most of that traffic. The appetite for fresh training data hasn't peaked; every new model generation needs a larger, more current corpus, and the web is where that corpus comes from. Independent trackers point the same way: bot-defense firm HUMAN reported that AI-driven web traffic grew 187% across 2025, so the rising training share sits on top of a fast-growing base of total AI requests.
What does a training crawl take? Text, mostly: the readable content of your pages, harvested in bulk with little regard for whether any single page is "important." That's the indiscriminate part. A training bot isn't trying to find your best page; it's trying to read all of them. For a content-heavy site, that can mean thousands of fetches that produce zero referral traffic and zero attribution.
This is the part of AI crawling site owners find hardest to accept. With Googlebot, the deal was legible: let it crawl, rank in search, get visitors. With a training crawler, the value flows one way. Your words improve a model; the model answers a user; the user never learns your site existed.
For more on how this training demand maps onto real model usage, our ChatGPT usage statistics and Claude adoption data show the consumer side of the same trend: the assistants these crawls ultimately feed.
Which industries get crawled most

Shopping sites get crawled more than any other kind. In the 28 days to June 22, 2026, shopping and general-merchandise sites absorbed 26.3% of all verified bot crawl traffic, the largest share of any industry, and roughly a quarter of everything Cloudflare's bots fetched. The three most-crawled industries together account for about two-thirds of verified bot crawl traffic.
| Industry | Share of verified bot crawl traffic |
|---|---|
| Shopping & General Merchandise | 26.3% |
| Internet & Telecom | 20.8% |
| Computer & Electronics | 18.9% |
| News, Media & Publications | 9.6% |
| Gambling | 6.5% |
| Business & Industry | 3.5% |
| Professional Services | 2.6% |
| Finance | 2.6% |
| Games | 2.2% |
| Other | 7.0% |
Why shopping? Because product catalogs are exactly the kind of structured, frequently-changing, high-volume content that both training and search crawlers reward. Prices move. Inventory turns over. Descriptions, reviews, and specs pile up. A model that wants to answer "what's the best running shoe under $120" needs current product data, and shopping sites are where it lives. The same logic explains why news and media (9.6%) draws heavy crawling. Fresh, factual, constantly-updated text is premium fuel.
The table above counts all verified bots. Narrow the lens to AI crawlers alone, across the entire first half of 2026, and shopping's lead gets sharper, not softer. Here is the AI-only cut from Cloudflare Radar:
| Vertical | Share of AI crawler requests (H1 2026) |
|---|---|
| Shopping & General Merchandise | 31.7% |
| Internet & Telecom | 17.0% |
| Computer & Electronics | 14.7% |
| News, Media & Publications | 9.1% |
| Business & Industry | 5.0% |
| Travel & Tourism | 3.9% |
| Professional Services | 3.3% |
| Finance | 2.9% |
| Gambling | 2.6% |
| Other | 9.9% |
Strip out the search engines and social-preview bots that pad the all-bots numbers, and AI crawlers concentrate on shopping even harder: 31.7% of their requests, versus 26.3% across all verified bots. The reason is the same one that makes product data valuable to a model in the first place. Note one new entrant in the AI-only view: Travel & Tourism (3.9%) cracks the top six, because itineraries, fares, and hotel inventory are exactly the live, structured data AI answer engines now field questions about.
Our own detection data adds the layer Cloudflare's can't: how much of the crawlable web those top industries actually sit on.
Shopify isn't the only engine behind that 26.3%. We also detect WooCommerce on 946,491 live domains, which means well over 3 million storefronts across just those two platforms, a deep and structured product corpus that training and search bots both want. The News, Media & Publications slice has a similar backbone: we detect WordPress on 6,049,999 live domains, roughly 63% of the CMS market, and it's the substrate under a large share of the world's editorial content. Content-rich industries get crawled hardest because content-rich platforms are what the open web is built on.
Search crawling is the fastest-growing purpose
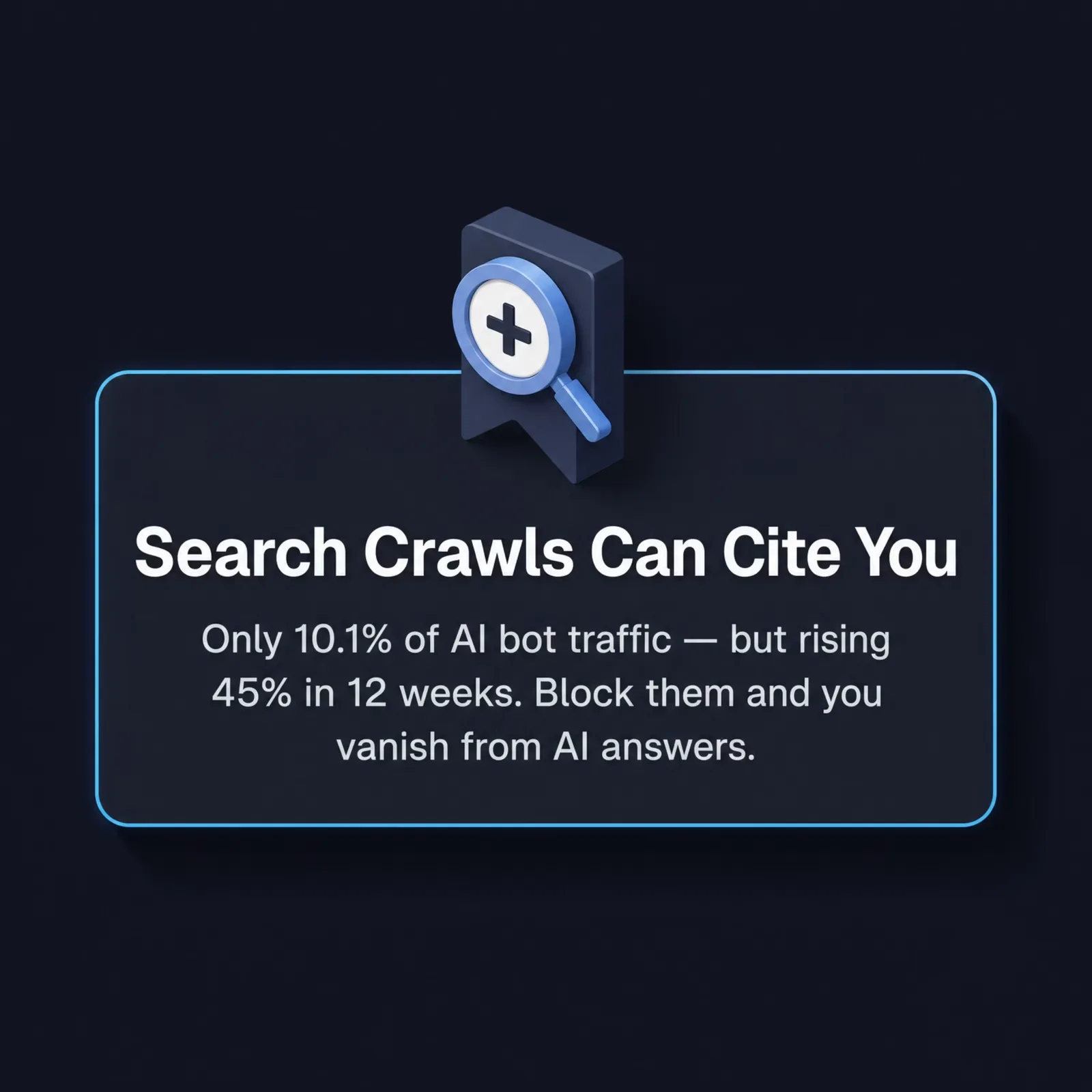
Search-purpose crawling is the fastest mover in the whole dataset. Across the first half of 2026, search crawling climbed from 7.5% to 10.7% of AI bot requests, a 43% relative jump, faster than any other purpose. At the same time, mixed-purpose crawling fell from 48.7% to 33.0%. Operators are splitting one do-everything crawler into clearer single-purpose bots, and the search bot is the one gaining ground.
This is the trend with the most upside for site owners. A search crawl is the kind that can cite you. When an AI answer engine fetches a live page to build a citation, that's search-purpose crawling. Unlike a training crawl, it can surface your brand inside the answer a user reads. The rise from 7.5% to 10.7% is a small absolute share, but the direction is the point: the slice of AI crawling that can actually send recognition (and sometimes a click) back to you is the one growing fastest.
That's why generative engine optimization, structuring content so AI answer engines can quote it, stops being optional. If more than 10% of AI crawl traffic is now hunting citable pages and that number is climbing, the pages you make easy to cite are the ones that earn visibility in AI answers.
Vercel's December 2024 study, The rise of the AI crawler, was the first widely-cited data on AI bot request volumes. Vercel measured a single crawler, GPTBot, making 569 million requests across its network in one month, with the major AI crawlers together reaching roughly 28% of Googlebot's request volume. It remains a useful benchmark for raw traffic. What it didn't break out was crawl purpose or the industry being crawled, the two dimensions this report leads with, eighteen months fresher.
What file types AI crawlers actually grab
AI crawlers are after words, not pictures. Across the first half of 2026, 72.8% of everything AI crawlers fetched from Cloudflare's network was HTML, the readable text of your pages. Nothing else comes close.
| Content type | Share of AI crawler fetches (H1 2026) |
|---|---|
| HTML | 72.8% |
| JSON | 7.2% |
| JavaScript | 5.4% |
| Images | 5.3% |
| Plain Text | 4.8% |
| XML | 1.9% |
| CSS | 1.6% |
| Other | 1.0% |
This confirms what the crawl-purpose split implies. Training and search crawlers both want language they can model and quote, and that language lives in your HTML. The small image share (5.3%) tells you most AI crawling today is still a text operation, though multimodal models are the reason to expect that number to climb. The slice I'd watch as a site owner is JSON at 7.2%: that is the signature of crawlers reading your structured data and APIs directly, product feeds, schema endpoints, the machine-readable layer an answer engine can parse most cleanly. If you serve clean JSON-LD and well-formed feeds, you are making yourself easier to cite, not just easier to read.
What your server actually says back to AI crawlers
Most AI crawlers get what they came for, but a meaningful slice now get turned away. Across the first half of 2026, 70.4% of AI crawler requests on Cloudflare's network returned a clean 200 OK. The rest is where the story is: 7.9% were met with a 403 Forbidden, the status a server returns when it is deliberately refusing the request, and another 0.7% hit a 429 Too Many Requests. Roughly one in twelve AI crawl requests is now actively refused.
| Server response | Share of AI crawler requests (H1 2026) | What it means |
|---|---|---|
| 200 OK | 70.4% | Request succeeded |
| 301 / 302 redirect | 11.1% | Sent to another URL |
| 403 Forbidden | 7.9% | Server deliberately refused the crawler |
| 404 Not Found | 3.5% | Page does not exist |
| 204 / 206 | 3.2% | No content / partial content |
| 429 Too Many Requests | 0.7% | Crawler was rate-limited |
| 304 Not Modified | 0.6% | Cached copy still valid |
| Other | 2.6% | — |
That 7.9% block rate is the clearest sign in the data that site owners have stopped treating AI crawlers as passive background traffic. A 403 is a choice, usually enforced at the CDN or firewall rather than in robots.txt, which a determined crawler can simply ignore. The 11.1% of requests that get redirected (301/302) are mostly harmless, the crawler following your URL structure, and the 3.5% that hit 404s are a reminder that AI crawlers chase stale links the same way search bots do. But the 403-and-429 combination, about 8.6% of all requests, is the number to watch: it is the open web pushing back, request by request.
Whether refusing crawlers is the right call, and how to do it without accidentally locking out the search bots that can cite you, is the subject of our dedicated guide to block AI crawlers in robots.txt. The response-code data just proves the pushback is already happening at scale.
How AI crawlers differ from traditional search bots
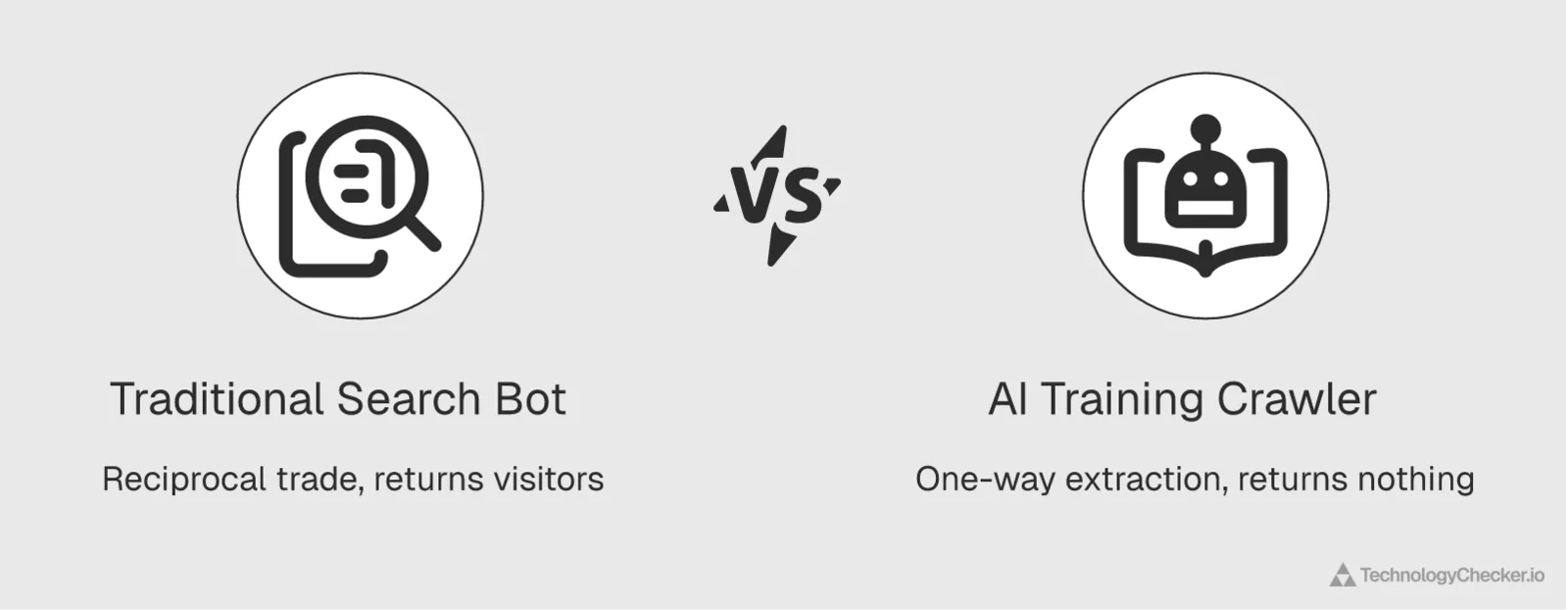
The core difference between an AI crawler and a traditional search bot is the direction of value. Googlebot is a fair trade: it reads your page, indexes it, and sends visitors back through search results. An AI training crawler reads your page and sends nothing back: no visit, no attribution, no ad impression. The data makes the asymmetry concrete: 52.3% of AI crawl traffic is training (no return trip) versus just 2.6% that's a real user fetching your specific page.
When I was building crawling systems on Google's Search team, the mental model was always reciprocal: a crawler took bandwidth, search sent traffic, and the exchange balanced out over time. That balance is what training crawlers break. They consume the same server resources, sometimes far more because they fetch indiscriminately, without the downstream traffic that made the cost worth paying.
It helps to think of AI crawlers in three tiers, by what they give back:
- Training crawlers, 52.3% of traffic, take your content for model training and return nothing. Pure extraction.
- Search crawlers, 10.1%, can cite you in an AI answer, so there's partial value back and sometimes a click.
- User Action fetches, 2.6%, mean a real person wanted your page right then, the closest thing to a traditional visit.
The practical upshot: blanket-blocking "AI bots" throws away the search tier (which can cite you) to stop the training tier (which can't). The two ride in on different user agents, and the policy that makes sense treats them differently. That's exactly where most site owners get it wrong.
What the crawl-purpose split means for site owners

The crawl-purpose split tells you to make a deliberate choice rather than a default one. With training at 52.3% and search at 10.1%, the real decision is whether you want to feed the models (training), be cited by the answer engines (search), or both. Those goals pull in different directions, and the right call depends on what your site is for.
If you sell something, the search tier is your friend and the training tier is a cost to manage. You want AI answer engines citing your product pages when someone asks for a recommendation, which means letting search crawlers in and structuring product data cleanly. Shopping sites already absorb 26.3% of bot crawl traffic, so fighting that entirely means surrendering presence in the AI answers your buyers increasingly trust.
If you publish proprietary research or paywalled analysis, the calculus flips. Training crawlers can absorb your hard-won work into a model that then answers the questions your content was meant to answer, without sending anyone to you. That's the case where restricting training crawlers while keeping search crawlers is the sharper move.
Controlling access is its own topic, and there's a right and wrong way to do it in robots.txt. Block the citation bots by accident and you remove your brand from AI answers entirely. We cover the exact directives, user agents, and pitfalls in our dedicated guide to block AI crawlers in robots.txt, so I won't repeat the how-to here. The one rule to carry over: blocking a training bot does not block the search bot, and the two often share a brand name but not a user agent.
For the bigger picture on how fast AI is moving into everyday business tooling, and the demand pressure behind all this crawling, our AI adoption trends report tracks the curve.
Frequently asked questions
What percentage of AI crawlers crawl to train models in 2026?
In Cloudflare Radar's 28-day window ending June 22, 2026, 52.3% of AI crawler requests were for training data, the single largest declared purpose, and more than the next two purposes combined. Averaged across the whole first half of 2026 the figure is 48.5%, because training has been climbing steadily all year, from 41.1% in January to 53.3% by late June. These figures are shares of verified AI-bot requests across Cloudflare's network, not of all web traffic.
How do AI crawlers affect shopping and ecommerce sites?
Shopping and general-merchandise sites absorb the heaviest AI crawl load of any industry, at 26.3% of verified bot crawl traffic in the 28 days to June 22, 2026. Product catalogs are structured, high-volume, and constantly updated, which is exactly what training and search crawlers reward. For ecommerce owners, that means real server load, but also a chance: search-purpose crawls can surface your products inside AI shopping answers.
What content do AI crawlers prioritize when crawling?
AI crawlers prioritize fresh, structured, text-rich content such as product catalogs, news, and reference material. The three most-crawled industries are Shopping (26.3%), Internet & Telecom (20.8%), and Computer & Electronics (18.9%), together roughly two-thirds of verified bot crawl traffic. Frequently-changing pages with clear, factual text are premium fuel because both training corpora and live AI answers depend on current data.
What file types do AI crawlers request most?
HTML, by a wide margin. Across the first half of 2026, 72.8% of what AI crawlers fetched from Cloudflare's network was HTML, the readable text of web pages. The next-largest formats are JSON (7.2%), JavaScript (5.4%), and images (5.3%). The low image share confirms AI crawling is still overwhelmingly a text operation, while the JSON share signals crawlers reading structured data and APIs directly. For site owners, the takeaway is that clean, semantic HTML and well-formed structured data are what AI crawlers actually consume.
How often do AI crawlers get blocked?
More often than most site owners realize. Across the first half of 2026, 7.9% of AI crawler requests on Cloudflare's network were met with a 403 Forbidden, and another 0.7% were rate-limited with a 429, so roughly one in twelve requests was actively refused. A further 3.5% hit 404 (page not found). The 403 rate is the clearest signal that owners are now enforcing access at the CDN or firewall level, not just asking politely through robots.txt.
Are AI crawlers different from traditional search bots?
Yes. The difference is the value exchange. Googlebot crawls to build a search index that sends visitors back to your page. An AI training crawler, which is 52.3% of AI crawl traffic, takes your content into a model and returns no visit and no attribution. Only the search tier (10.1%) and User Action fetches (2.6%) can send anything back. They arrive on different user agents, so they can be governed separately.
Should B2B SaaS sites block AI crawlers?
Not as a blanket policy. Blocking all "AI bots" throws away the search-purpose crawlers (10.1% of traffic, and up 43% across the first half of 2026) that can cite you in AI answers, just to stop the training crawlers that can't. Most B2B SaaS sites benefit from allowing search and user-fetch bots while deciding on training bots case by case. The control specifics live in our robots.txt guide.
How do you detect and analyze AI crawler traffic?
AI crawler traffic is identified by user agent and verified against the operator's published IP ranges, the method behind Cloudflare's verified-bot classification. Server logs and a CDN or analytics layer that labels known bots will show you which purposes (training, search, user-fetch) are hitting your site and how often. Verifying the IP, not just trusting the user-agent string, is what separates a real GPTBot from a spoofed one.
Do AI crawlers respect robots.txt files?
Most major, verified AI crawlers honor robots.txt, but compliance isn't universal and some bots use stealth or undeclared agents. Treat robots.txt as the first layer, not a hard wall, and pair it with CDN or firewall rules if you truly need to block a crawler. Remember that a robots.txt block aimed at a training bot won't stop a separate search bot from the same company unless you name its user agent too.
What is the impact of AI crawlers on SEO and AI visibility?
AI crawlers split your visibility into two tracks. Training crawls (52.3%) feed the models behind AI answers but send no direct traffic. Search crawls (10.1%, the fastest-growing purpose) decide whether you get cited in those answers. Classic SEO still wins you the click from search results; making content easy for search-purpose crawlers to quote is what wins you a mention inside the AI answer. That's increasingly a separate, parallel goal.
What are the trends in AI crawler behavior for 2026?
Two trends stand out across the first half of 2026. Training crawling rose from 41.1% to 53.3%, and search crawling rose fastest in relative terms (7.5% to 10.7%, a 43% jump). Meanwhile mixed-purpose crawling fell from 48.7% to 33.0%, having started the year as the single largest purpose. The pattern is operators splitting do-everything crawlers into clearer single-purpose bots, which makes per-purpose access policy both possible and necessary.
David Thomson
CTO

