We Analyzed robots.txt Across Cloudflare's Network: Which AI Crawlers Get Blocked Most and Why (July 2026 Update)
robots.txt analysis across Cloudflare's network, refreshed for the Q2 2026 close with year-over-year data: AI crawler-to-refer ratios converged (Anthropic's collapsed 18x but stayed worst), the 403 block rate on AI bots more than doubled, and a data-driven framework for blocking AI bots.
Published •Updated •52 min read
After analyzing robots.txt directives across Cloudflare's global network in Q1 2026, we found that GPTBot is the most blocked AI crawler, Anthropic's ClaudeBot crawls 20,583 pages for every single referral it returns, and 89.4% of all AI crawler traffic serves training or mixed purposes rather than search. The full data on what AI crawlers actually want — the crawl-purpose split and the industries hit hardest — sits in our AI crawler statistics report. These findings reshape how every website owner should think about their robots.txt AI crawlers policy.
Updated June 1, 2026 — full-month May data: Bytespider nearly doubled to 10.25% of AI crawler traffic and is now the #4 crawler; GPTBot rebounded to reclaim #3 from ClaudeBot; Anthropic launched a dedicated search crawler (Claude-SearchBot, 2.22%); the search-and-user-action slice that can return traffic broke above its long-standing ~10% ceiling to 11.9%; and Shopping has held ~31% of all AI crawling every single month of 2026. The Q1 baselines below are unchanged — see the May update section directly after this list for the full trajectory.
Key findings from our Q1 2026 robots.txt analysis:
- GPTBot is the most blocked AI crawler, appearing in more DISALLOW rules than any other AI bot, followed by CCBot, ClaudeBot, and Google-Extended
- Anthropic's crawl-to-refer ratio is 20,583:1 — ClaudeBot crawls 20,583 pages for every single referral it sends back to publishers. OpenAI is 1,255:1. Meta sends zero referrals.
- 89.4% of AI crawler traffic is training or mixed-purpose — only 8% is search-related and just 2.2% responds to actual user queries
- 30.6% of all web traffic is bots — AI crawlers now account for a growing share. Googlebot alone generates 35.2% of all AI-categorized bot traffic.
- Retail absorbs 28.1% of AI crawling — more than double any other industry. Computer Software is second at 13.6%.
- ClaudeBot blocking grew fastest during Q1 — its share of DISALLOW rules rose from 9.6% in January to 10.1% by March, while GPTBot stayed flat
- Some AI bots are explicitly welcomed — PerplexityBot and ChatGPT-User appear more in ALLOW rules than DISALLOW, likely because they return traffic
Where AI-Crawler Blocking Stands at the Q2 2026 Close, With the Year-Over-Year Picture
Updated July 2, 2026. Q2 2026 closed on June 30. This section aggregates the full calendar quarter (April 1 through June 30) and, for the first time, adds a year-over-year layer against the same window in 2025. It sits on top of the June 1 and Q1 layers below, which are preserved unchanged. One honest boundary up front: Cloudflare exposes historical windows for the AI-bot traffic datasets (crawl-to-refer ratios, response codes, purpose, user-agent share) but not for the robots.txt directive rankings, which return only a rolling single-day snapshot. So the year-over-year story here comes from what crawlers actually did and what servers actually returned, not from directive-share deltas, and the directive snapshot is reported at the Q2 close without a YoY. That is the stronger read anyway, because robots.txt is voluntary and enforced 403s are the harder signal.
The June 1 update and the full Q1 2026 baseline that follow this section are unchanged. Read on for the trajectory that produced these year-end numbers.
The crawl-to-refer ratios converged, and the worst offender improved most
The single metric this report is built around is the crawl-to-refer ratio: pages a bot crawls per referral it sends back. Over a full year it moved more than any other number in the dataset, and it moved toward the middle from both ends.
| Operator | Q2 2025 | Q1 2026 | Q2 2026 | Year-over-year |
|---|---|---|---|---|
| Anthropic | 91,702:1 | 20,583:1 | 5,143:1 | Collapsed about 18x, still the worst |
| OpenAI | 1,257:1 | 1,255:1 | 870:1 | Improved about 31% |
| Perplexity | 230:1 | 111:1 | 153:1 | Improved YoY, ticked up from Q1 |
| Mistral | 1.6:1 | 24:1 | 63:1 | Worsened sharply |
| Microsoft | 43:1 | 32:1 | 33:1 | Held near flat |
| Yandex | 15:1 | 21:1 | 23:1 | Worsened |
| Baidu | 1.2:1 | 5.2:1 | 10.5:1 | Worsened |
| ByteDance | 1.8:1 | 3.5:1 | 9.1:1 | Worsened, from near 1:1 to 9:1 |
| 17:1 | 5.0:1 | 5.0:1 | Improved to a steady 5:1 | |
| DuckDuckGo | 0.27:1 | 1.5:1 | 1.7:1 | Worsened, still near 2:1 |
Source: Cloudflare Radar — bots/crawlers/summary/crawl_refer_ratio, RATIO of crawl requests to referrals. Q2 2026 = 2026-04-01 to 06-30, Q1 2026 = 2026-01-01 to 03-31, Q2 2025 = 2025-04-01 to 06-30. Pulled 2026-07-02.
Two things happened at once. The extractive giants got far less extractive: Anthropic fell from 91,702:1 to 5,143:1, OpenAI from 1,257:1 to 870:1, Perplexity from 230:1 to 153:1, and Google settled at a clean 5:1. At the same time the bots that used to sit near a healthy 1:1 got more extractive: ByteDance went from 1.8:1 to 9.1:1, Baidu from 1.2:1 to 10.5:1, Mistral from 1.6:1 to 63:1, and even DuckDuckGo drifted from 0.27:1 to 1.7:1. The gap between the most and least extractive crawler compressed from roughly 340,000:1 a year ago to about 3,000:1 now, a field converging toward the middle rather than splitting apart.
The headline is Anthropic. The bot this entire report is built around, the one we told you to block at 20,583:1, improved its ratio roughly 18x in a year to 5,143:1. That is exactly the move our Q1 analysis said would reduce its blocking, and it lines up with Anthropic launching Claude-SearchBot, a referral-sending crawler that finally gives ClaudeBot's training extraction a counterpart. But read the number carefully: 5,143:1 is still about 1,000x worse than Google's 5:1. Anthropic went from astronomically extractive to merely the worst of the majors. The recommendation is unchanged: block ClaudeBot for training, allow Claude-SearchBot for search.
Are sites fighting back? The 403 rate on AI crawlers more than doubled
robots.txt is a request. An HTTP 403 is an answer. The cleaner measure of whether the web is pushing back is not what directives sites write but what response codes their servers actually return to AI crawlers. Here is the full-quarter response mix for AI bots specifically:
| AI-bot response | Q2 2025 | Q1 2026 | Q2 2026 | Year-over-year |
|---|---|---|---|---|
| 200 OK | 81.72% | 69.21% | 71.74% | Fell about 10 points |
| 2xx (success, all) | 83.26% | 72.06% | 75.19% | Fell about 8 points |
| 403 Forbidden | 3.63% | 7.33% | 8.56% | More than doubled |
| 404 Not Found | 3.39% | 3.57% | 3.45% | Flat |
| 429 Rate-limited | 0.51% | 0.60% | 0.84% | Rose |
| 4xx (client error, all) | 7.53% | 11.49% | 12.85% | Up about 5 points |
Source: Cloudflare Radar — ai/bots/summary/response_status, PERCENTAGE of AI-bot requests. Windows as above.
The 403 Forbidden rate, the code a server returns when it deliberately refuses a request, more than doubled year over year, from 3.63% to 8.56% of all AI-bot requests. Rate-limiting (429) rose too, and successful 2xx responses fell about 8 points. Publishers are not just writing rules, they are enforcing them at the edge.
But the scale matters, and here is where this report can correct a common misreading. Our own AI adoption analysis reports that across all crawlers Cloudflare tracks, scrapers and SEO tools and vulnerability scanners included, the 4xx rate hit 35.8%, more than one in three requests blocked. For AI bots specifically the 4xx rate is far lower, about 12.85%. The named AI crawlers (Googlebot, GPTBot, ClaudeBot) are actually blocked less than the crawler population at large, because they mostly request real, existing URLs rather than probing for holes. The pushback against AI crawlers is real and accelerating, the 403 rate doubling proves it, but AI crawlers are not yet blocked as hard as the internet's general bot noise. That is the honest scale of the standoff.
The traffic leaderboard reordered, and Anthropic climbed to #2
The AI crawler field looks different than it did a year ago. We cover the four-layer AI-adoption picture in depth in our AI adoption trends report; here is the crawler cut that matters for blocking decisions:
| AI Bot | Q2 2025 | Q1 2026 | Q2 2026 | Year-over-year |
|---|---|---|---|---|
| Googlebot | 57.20% | 35.19% | 27.49% | Grip halved, still #1 |
| ClaudeBot | 8.30% | 11.31% | 13.87% | Rose to #2 |
| Meta-ExternalAgent | 6.27% | 13.94% | 12.70% | Doubled |
| GPTBot | 11.40% | 12.54% | 10.23% | Slipped, the only major to lose |
| Bingbot | 7.02% | 9.21% | 8.11% | Held |
| Bytespider | 2.37% | 3.48% | 7.91% | Tripled |
| Applebot | 0.92% | 3.55% | 7.36% | Rose roughly 8x |
| Amazonbot | 3.83% | 4.86% | 5.08% | Ticked up |
| Claude-SearchBot | n/a | n/a | 2.14% | New, Anthropic's search bot |
Source: Cloudflare Radar — ai/bots/summary/user_agent, PERCENTAGE of AI-bot requests. Windows as above.
Googlebot's share of AI-bot traffic more than halved over the year, from 57.20% to 27.49%, as the field went multipolar. ClaudeBot rose to #2 (13.87%), passing GPTBot, which is the only major crawler to lose share year over year. Bytespider tripled and Applebot rose roughly eightfold off a tiny 2025 base, both confirming over a full year the surges the monthly layers below first caught. Behind the leaderboard, the purpose mix shifted the same direction: training crawls overtook mixed-purpose as the #1 declared reason (44.86%, up from 28.73% a year ago), while the referral-capable Search slice nearly doubled to 9.13%. And bots kept gaining on humans: 33.21% of all web traffic was automated this quarter, up from 30.39% a year ago.
The robots.txt directive snapshot at the Q2 close
Finally, the directive rankings themselves. This is the one dataset without a year-over-year cut: Cloudflare's robots.txt endpoint returns a rolling single-day snapshot, not a windowed aggregate, so the numbers below are the state of the web's robots.txt files on June 29, 2026, the Q2 close, and cannot be compared like-for-like to a year earlier. Among parsed files, the most-named AI user-agents were:
GPTBot 690, ClaudeBot 594, Google-Extended 558, CCBot 554, Bytespider 467, meta-externalagent 418, PerplexityBot 415, Googlebot 412, Amazonbot 402, Applebot-Extended 386. By domain category, Technology (938 domains), Business (806), and Ecommerce (287) publish the most AI-targeting rules.
Source: Cloudflare Radar — robots_txt/top/user_agents/directive and robots_txt/top/domain_categories, RAW counts, single-day snapshot dated 2026-06-29.
GPTBot is still the most-named AI crawler in robots.txt, as it has been since Q1. But the cluster just behind it reshuffled again: ClaudeBot (594) moved back ahead of CCBot (554), and Google-Extended (558) also edged past CCBot, reversing the June 1 order where CCBot led that pack. Every count is higher than the June 1 sample (GPTBot 529, CCBot 463, ClaudeBot 457), consistent with more files naming more bots. This is the same lesson the weekly data taught all quarter: the top blocking cluster is a genuine tie that trades places month to month. Treat the rank order as noise, and the direction, steadily more bots named in more files, as the signal.
The Q2 bottom line: over a full year the standoff moved on both sides. The worst crawlers got materially less extractive, the crawl-to-refer ratios converged and Anthropic's improved 18x, while publishers enforced harder at the edge, the 403 rate on AI bots more than doubling. The economic logic this report is built on played out in the data: improve your crawl-to-refer ratio, or collect more 403s.
How Did AI Crawler Blocking and Traffic Share Shift Through May 2026?
According to Cloudflare Radar's robots.txt analysis, the AI crawler field reshuffled hard in May 2026: Bytespider (ByteDance) nearly doubled to 10.25% of AI bot traffic and vaulted to the #4 crawler, GPTBot rebounded to 11.48% and reclaimed #3 from ClaudeBot, and Applebot's headline April surge half-unwound (9.23% to 7.01%). A new user-agent, Claude-SearchBot, showed up at 2.22% — Anthropic now runs a dedicated search crawler, which changes one of the recommendations in this report. We re-pulled every robots.txt and AI-crawler metric for the full month of May 2026. Updated June 1, 2026.
At the infrastructure level, May made me walk back an April call. In the April update I wrote that Applebot was the bot we'd re-balanced our rate-limit budgets around. One month later Applebot retreated and Bytespider is the bot that actually broke our capacity assumptions, jumping from 5.73% to 10.25% of AI crawler traffic in thirty days. That's the honest lesson of running this scan every month: a single month of crawler movement is a hypothesis, not a trend. April looked like the Applebot story. May was the Bytespider story. The publisher-side robots.txt rules still haven't caught up to either.
GPTBot, which we'd written off as a two-month decline, rebounded to 11.48% in May and took back #3 from ClaudeBot. The order of who-gets-blocked-hardest kept moving too: Google-Extended edged back ahead of Bytespider in fully-blocked share, reversing the April crossover we'd flagged. None of these are clean trends. They're a field that's still settling.
Which Cloudflare Radar Metrics Changed Most From Q1 2026 Through May 2026?
| Metric | Q1 2026 | April 2026 | May 2026 | Net direction |
|---|---|---|---|---|
| Googlebot share of AI crawler traffic | 35.2% | 30.28% | 27.26% | Three straight monthly declines |
| Meta-ExternalAgent share | 13.9% | 14.91% | 13.23% | Round-tripped back to ~Q1 |
| GPTBot share | 12.5% | 9.84% | 11.48% | Rebounded — back to #3 |
| Bytespider share | 3.5% | 5.73% | 10.25% | Nearly tripled — now #4 |
| ClaudeBot share | 11.3% | 11.69% | 9.73% | Pulled back to #5 |
| Bingbot share | 9.2% | 8.04% | 8.45% | Stabilized |
| Applebot share | 3.6% | 9.23% | 7.01% | April surge half-unwound |
| Amazonbot share | 4.9% | 4.47% | 5.29% | Ticked back up |
| Claude-SearchBot share | — | — | 2.22% | New — Anthropic search bot |
| OAI-SearchBot share | 2.2% | 1.91% | in tail | Slipped out of the top tier |
| Training share of crawl purpose | 45.0% | 51.51% | 51.80% | Held high |
| Mixed-purpose share | 44.4% | 38.32% | 35.71% | Kept declining |
| Search + User Action combined | 10.2% | 9.72% | 11.91% | Broke above the ~10% ceiling |
| GPTBot — fully-blocked DISALLOW share | 5.52% | 5.20% | 4.71% | Eased (longer tail) |
| CCBot — fully-blocked DISALLOW share | 5.08% | 5.14% | 4.28% | Eased |
| ClaudeBot — fully-blocked DISALLOW share | 4.88% | 4.59% | 4.18% | Eased |
| Bytespider — fully-blocked DISALLOW share | 4.23% | 4.41% | 3.70% | Fell behind Google-Extended again |
| Google-Extended — fully-blocked DISALLOW share | 4.44% | 4.23% | 3.82% | Retook the spot above Bytespider |
| Retail share of AI crawling (industry) | 28.1% | 28.89% | 28.71% | Lead intact |
| Shopping vertical share of AI crawling | 31.3% | 31.89% | 31.73% | Stable ~32% all year |
| Domains blocking (raw daily sample) | 4,047 files | 4,128 files | 4,072 files | Sample steady |
Which April 2026 Narratives Did May Reverse, Confirm, or Extend?
1. We called Applebot the new top-five threat in April. May took half of it back. Applebot went 3.6% (Q1) to 9.23% (April) to 7.01% (May). It's still well above its Q1 level, so the "stop treating Applebot as an afterthought" advice stands. But the "Applebot is closing on GPTBot" framing was a one-month spike we over-weighted, and it fell out of the top five entirely in May. The bot that actually kept climbing was Bytespider.
2. Bytespider is the real surge story, not Applebot. Bytespider went 3.5% to 5.73% to 10.25%, nearly tripling over the period and almost doubling in May alone. It's now the #4 AI crawler, ahead of ClaudeBot, and it does this while being one of the most fully-blocked bots in robots.txt (3.70% of DISALLOW rules). ByteDance is crawling at scale straight through the blocks. If you sized capacity off the Q1 or even the April numbers, Bytespider is the line item that's now badly wrong.
3. GPTBot's "structural decline" reversed. In April we noted GPTBot had fallen to #4 and called the OpenAI-versus-everyone framing a 2024-2025 story. In May GPTBot rebounded to 11.48% and retook #3 from ClaudeBot. Two consecutive months of decline turned out to be a dip, not a trend — the same churn we flagged in the May 2026 ChatGPT statistics update. We keep the monthly cadence precisely because calls like this flip.
4. The April blocking crossovers reverted. April produced two ranking changes — "Bytespider passed Google-Extended in fully-blocked share" and "ClaudeBot overtook CCBot by raw mentions" — and both reversed in the June 1 sample. Google-Extended (3.82%) is back ahead of Bytespider (3.70%) in fully-blocked share, and CCBot (463 mentions) edged back ahead of ClaudeBot (457). The top blocking cluster is genuinely tied and noisy month to month. Treat the rank order as a coin flip and the magnitudes as the signal.
5. Anthropic launched a search crawler, and that's new. Claude-SearchBot appeared in May at 2.22% of AI crawler traffic. This report's Q1 framework assumed Anthropic ran only a training bot (ClaudeBot) with no referral-sending counterpart. That's no longer true, and it changes the ClaudeBot recommendation — covered in the decision framework and FAQ below.
Which Patterns Held Through May 2026?
The training-versus-referral thesis held, with one crack worth naming. Training + Mixed Purpose was 87.51% in May (51.80% Training + 35.71% Mixed), down from 89.83% in April and 89.4% in Q1. The slice that can send traffic back — Search + User Action — rose to 11.91%, its first clear move above the ~10% ceiling this report has described since Q1. Anthropic's new Claude-SearchBot is part of why: more operators now run a dedicated search crawler beside their training bot. The thesis still holds (roughly seven of every eight AI crawl requests return nothing to publishers), but the referral-capable share is finally widening instead of sitting flat.
Retail's lopsided lead held: 28.71% of AI crawler traffic by industry in May, still more than double the next category. The "blocked but rising" pattern held too — Meta-ExternalAgent (13.23%) and Bytespider (10.25%) both carry heavy traffic while ranking among the most-blocked bots in robots.txt.
How Do the May 2026 Numbers Affect the Q1 2026 Findings?
The Q1 baselines below are still the right anchor for understanding where Q2 started, and we've left them in place with inline May notes where the ranking or magnitude moved. Three things changed enough to act on: Bytespider is now a top-four capacity concern rather than a footnote, GPTBot is back in the top three, and Anthropic now runs a search bot, so the old "blocking ClaudeBot has no referral downside" advice needs a caveat. The crawl-to-refer ratios and methodology are unchanged; the relative urgency of each recommendation is not.
Every robots.txt file is a policy decision. Allow this bot. Block that one. Ignore the rest. But most website owners are making these decisions with almost no data. We decided to fix that.
As CTO of TechnologyChecker.io, I oversee the crawling infrastructure that scans tens of millions of domains every month, 29.9 million of them currently active. We see robots.txt files at scale every single day. But to understand the full picture, not just what our crawler encounters but what the entire internet is doing, we pulled Q1 2026 data from Cloudflare Radar, which aggregates traffic patterns across 81 million HTTP requests per second and 67 million DNS queries per second through 330 cities in 125+ countries.
Here's what the data actually says.
Which AI crawlers are blocked most in robots.txt?
GPTBot leads all AI crawlers in DISALLOW rules, but it also leads in ALLOW rules. The internet is genuinely split on OpenAI's bot. We pulled robots.txt directive data from Cloudflare Radar for the full Q1 2026 period (January 1 through March 31). Among all domains with DISALLOW rules targeting AI crawlers, here's the share each bot accounts for:
| AI Crawler | Operator | DISALLOW Share | ALLOW Share | Net Sentiment |
|---|---|---|---|---|
| GPTBot | OpenAI | 5.52% | 5.65% | Mixed — blocked AND allowed frequently |
| CCBot | Common Crawl | 5.08% | — | Mostly blocked |
| ClaudeBot | Anthropic | 4.88% | 4.24% | Slightly more blocked than allowed |
| Google-Extended | 4.44% | 4.29% | Slightly more blocked than allowed | |
| Bytespider | ByteDance | 4.23% | — | Mostly blocked |
| meta-externalagent | Meta | 3.82% | — | Blocked, never explicitly allowed |
| Amazonbot | Amazon | 3.80% | — | Mostly blocked |
| Applebot-Extended | Apple | 3.67% | — | Mostly blocked |
| Googlebot | 2.92% | 9.40% | Overwhelmingly allowed |
June 2026 update — the blocking cluster reverted to a near-tie: On June 1, Cloudflare parsed 4,072 robots.txt files. Top AI-bot mentions (fully + partially blocked): GPTBot 529, CCBot 463, ClaudeBot 457, Google-Extended 417, Bytespider 395. CCBot edged back ahead of ClaudeBot, reversing April's crossover. By fully-blocked DISALLOW share across the AI category in May, the order was GPTBot 4.71%, CCBot 4.28%, ClaudeBot 4.18%, Google-Extended 3.82%, Bytespider 3.70% — and Google-Extended moved back ahead of Bytespider, reversing the other April crossover. Every top bot's share eased a few tenths of a point because site owners now name a longer tail of AI user-agents: the "other" bucket is 67% of AI DISALLOW mentions. Less concentration at the top, not less blocking overall.
On a single day (March 30, 2026), Cloudflare parsed 4,047 robots.txt files. Of those, 557 mentioned GPTBot (13.8%), 466 mentioned ClaudeBot (11.5%), 452 mentioned CCBot (11.2%), and 434 mentioned Google-Extended (10.7%).
Three patterns stand out.
GPTBot leads both blocking AND allowing. It's the most frequently mentioned AI crawler in robots.txt, period. Some sites block it, others explicitly allow it. That's because GPTBot is actually two things: a training crawler and a gateway to ChatGPT search results. Sophisticated site owners are starting to differentiate, blocking GPTBot (training) while allowing OAI-SearchBot (search). We'll come back to this.
Meta-ExternalAgent never appears in ALLOW rules. Every other major AI crawler shows up in both ALLOW and DISALLOW directives. Meta's bot is exclusively blocked or ignored. Nobody is going out of their way to welcome it. Given that it sends zero referral traffic (more on that below), this makes sense.
Googlebot is overwhelmingly allowed. 9.4% of ALLOW rules mention Googlebot compared to just 2.9% of DISALLOW rules, a 3.2x ratio favoring access. Website owners understand that blocking Googlebot means disappearing from search results entirely. No other bot gets this kind of preferential treatment.
External context: According to a BuzzStream study of top publishers, 79% of top news sites now block AI training bots via robots.txt, while only 14% of publishers block all AI bots completely. Our Cloudflare Radar data shows a similar selective blocking pattern across all industries, not just publishers.
DISALLOW rules. Use this to track which bots the web is currently rejecting hardest.Why are websites blocking AI crawlers? The crawl-to-refer ratio tells the story

Blocking decisions aren't random. There's a straightforward economic calculation behind them: how much does this bot take from my site (crawl volume) versus how much does it send back (referral traffic)? Cloudflare Radar tracks this as a crawl-to-refer ratio. (For the bigger referral picture across all sources, see our search engine market share 2026 — Google still drives 87.5% of organic referrals.)
Here's the Q1 2026 data:
| Operator | Crawl-to-Refer Ratio | Translation | Trend vs Q4 2025 |
|---|---|---|---|
| Anthropic | 20,583:1 | Crawls 20,583 pages per 1 referral sent | Worsened |
| OpenAI | 1,255:1 | Crawls 1,255 pages per 1 referral sent | Improved slightly |
| Perplexity | 111:1 | Crawls 111 pages per 1 referral sent | Stable |
| Microsoft | 32:1 | Crawls 32 pages per 1 referral sent | Stable |
| Mistral | 24:1 | Crawls 24 pages per 1 referral sent | — |
| Yandex | 21:1 | Crawls 21 pages per 1 referral sent | Stable |
| Baidu | 5.2:1 | Crawls 5.2 pages per 1 referral sent | Stable |
| 5.0:1 | Crawls 5 pages per 1 referral sent | Stable | |
| ByteDance | 3.5:1 | Crawls 3.5 pages per 1 referral sent | Stable |
| DuckDuckGo | 1.5:1 | Nearly 1-to-1 | Stable |
Read those numbers carefully.
Anthropic crawls 20,583 pages for every single referral it sends back. That's not a typo. ClaudeBot is the most aggressive pure consumer of web content relative to what it returns. For context, Google crawls 5 pages per referral. DuckDuckGo is nearly 1-to-1. Anthropic's ratio is 4,117x worse than Google's.
OpenAI is 1,255:1 — better than Anthropic but still extractive. The ratio has improved slightly since ChatGPT began sending referral traffic through its browse and search features, but it's still 251x worse than Google.
Perplexity is the best among dedicated AI companies at 111:1. That's still 22x worse than Google, but it's a fundamentally different model. Perplexity's entire product is a search engine that links to sources. The ratio reflects this.
The correlation between blocking and ratio is almost perfect. The bots with the worst crawl-to-refer ratios (Anthropic, OpenAI) are the most blocked in robots.txt. The bots with good ratios (Google, DuckDuckGo, ByteDance) are almost never blocked. The data tells website owners exactly what we'd expect: they tolerate crawling that sends traffic back, and they block crawling that doesn't.
Looking at the daily timeseries data, Anthropic's ratio was volatile throughout Q1, spiking above 100,000:1 on some days in January and gradually declining toward 10,000-15,000:1 by March. That's still astronomically high but trending in the right direction. If Anthropic wants to reduce blocking, improving this ratio is the single most effective thing they can do.
What to do with this insight: Use crawl-to-refer ratios as your primary decision metric. Block bots with ratios above 1,000:1 (training-focused crawlers). Allow bots under 200:1 (search-focused crawlers that return traffic). Review quarterly as ratios shift.
robots.txt, transparently identifies itself, and self-rate-limits — sorted by traffic volume. "Polite" vs "aggressive" bots, at a glance.How much traffic do AI crawlers actually generate?
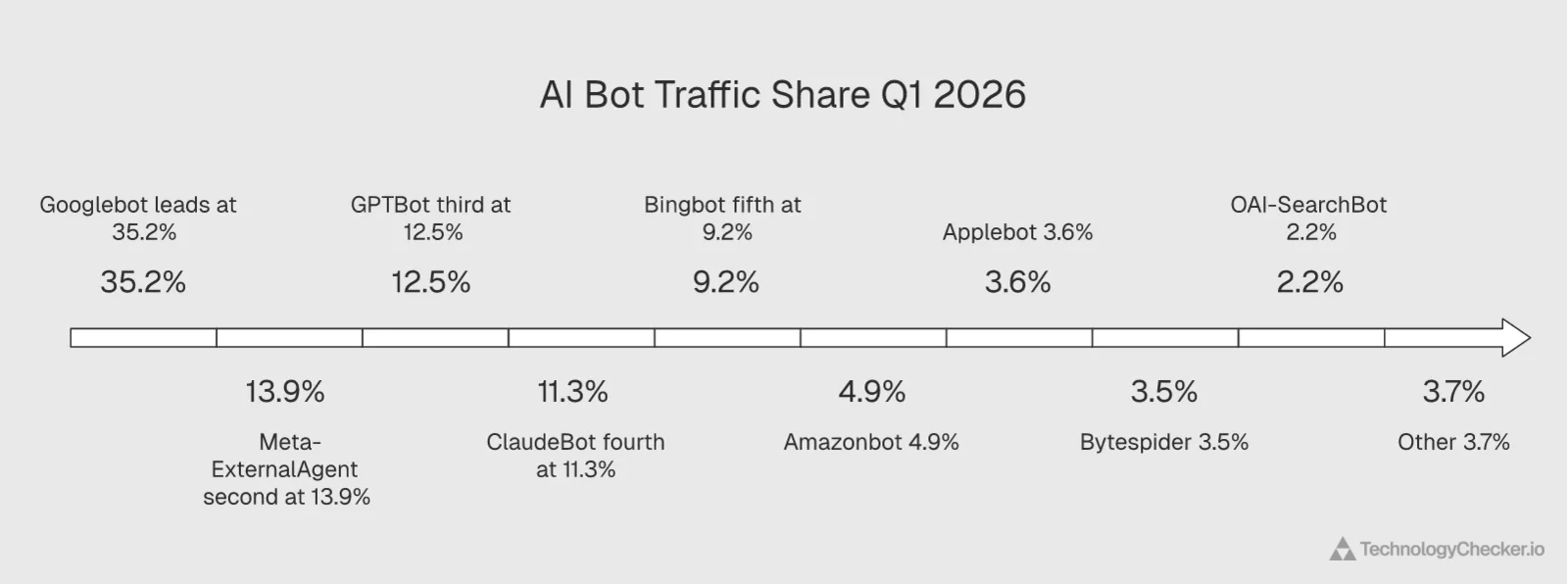
Before discussing whether to block or allow AI crawlers, you need to know how much traffic they actually generate. Here's the AI bot traffic breakdown for Q1 2026:
| AI Bot | Traffic Share | Operator | Primary Purpose |
|---|---|---|---|
| Googlebot | 35.2% | Search indexing + AI training | |
| Meta-ExternalAgent | 13.9% | Meta | AI training (zero referrals) |
| GPTBot | 12.5% | OpenAI | AI training + ChatGPT data |
| ClaudeBot | 11.3% | Anthropic | AI training |
| Bingbot | 9.2% | Microsoft | Search indexing + Copilot |
| Amazonbot | 4.9% | Amazon | Alexa + product data |
| Applebot | 3.6% | Apple | Siri + Apple Intelligence |
| Bytespider | 3.5% | ByteDance | AI training + TikTok data |
| OAI-SearchBot | 2.2% | OpenAI | ChatGPT search (sends referrals) |
| Other | 3.7% | Various | Various |
May 2026 update — Bytespider stormed the top five:
AI Bot Q1 2026 April 2026 May 2026 Δ vs April Googlebot 35.2% 30.28% 27.26% -3.02 pts Meta-ExternalAgent 13.9% 14.91% 13.23% -1.68 pts GPTBot 12.5% 9.84% 11.48% +1.64 pts Bytespider 3.5% 5.73% 10.25% +4.52 pts ClaudeBot 11.3% 11.69% 9.73% -1.96 pts Bingbot 9.2% 8.04% 8.45% +0.41 pt Applebot 3.6% 9.23% 7.01% -2.22 pts Amazonbot 4.9% 4.47% 5.29% +0.82 pt Claude-SearchBot — — 2.22% new entry The April top-five was Googlebot, Meta-ExternalAgent, ClaudeBot, GPTBot, Applebot. The May top-five is Googlebot, Meta-ExternalAgent, GPTBot, Bytespider, ClaudeBot. Bytespider nearly doubled in a single month to claim #4, GPTBot rebounded past ClaudeBot, and Applebot dropped out of the top five entirely. A new Anthropic user-agent, Claude-SearchBot, appeared at 2.22%. If you sized rate-limit budgets off the Q1 or April numbers, Bytespider is the line item that's now badly understated — it's the bot to plan capacity around in Q3.
Googlebot alone generates 35.2% of all AI-categorized bot requests. This is critical context for the robots.txt discussion. Google operates in a dual role: it crawls for search indexing (which everyone wants) and for AI training through Google-Extended (which some want to block). The Google-Extended user agent lets site owners block the AI training component while keeping search indexing intact. 10.7% of analyzed robots.txt files already use this distinction.
Meta-ExternalAgent at 13.9% sends zero referral traffic. It's the second-highest volume AI crawler and returns nothing to publishers. Combined with its absence from ALLOW rules, the data paints a clear picture: Meta is extracting content at scale with no reciprocal benefit to site owners. According to SEOmator's analysis of Cloudflare data, Meta-ExternalAgent surged from 8.5% to 11.6% of global AI bot traffic between December 2025 and January 2026 alone, a 36% relative jump in 30 days.
OpenAI runs two separate bots. GPTBot (12.5%) handles training data collection, while OAI-SearchBot (2.2%) handles ChatGPT search queries that can send referral traffic. Forward-thinking site owners are blocking GPTBot while allowing OAI-SearchBot, getting ChatGPT search visibility without providing free training data. We see this pattern in the ALLOW data: OAI-SearchBot appears in 4.22% of ALLOW rules, nearly matching GPTBot's 5.65%.
And all of this sits within a broader context: 30.6% of all web traffic in Q1 2026 was bots. Not just AI crawlers, all bots combined. According to HUMAN Security's 2026 State of AI Traffic report, AI-driven traffic grew 187% in 2025, and agentic AI traffic specifically grew 7,851% year-over-year. The scale is accelerating.
What are AI crawlers actually doing with your content?

Not all AI crawling is the same. Cloudflare Radar categorizes AI bot traffic by declared crawl purpose:
| Crawl Purpose | Share of AI Traffic | What It Means |
|---|---|---|
| Training | 45.0% | Collecting data to train language models |
| Mixed Purpose | 44.4% | Combines training, indexing, and product features |
| Search | 8.0% | Powering AI search products (Perplexity, ChatGPT Browse) |
| User Action | 2.2% | Fetching pages in response to real user queries |
| Undeclared | 0.4% | Purpose not specified in user agent |
May 2026 update — the referral-capable slice finally widened: Training held at 51.80% and Mixed Purpose fell again to 35.71%, so Training + Mixed = 87.51% (down from 89.83% in April). The slice that can return traffic — Search (9.33%) plus User Action (2.58%) — rose to 11.91%, its first clear move above the ~10% ceiling we've tracked since Q1. Anthropic's new Claude-SearchBot is part of the reason: more operators now run a dedicated search crawler beside their training bot. The thesis holds (about seven of every eight AI crawl requests still return nothing to publishers), but for the first time the referral-capable share is widening instead of sitting flat.
89.4% of AI crawler traffic is training or mixed-purpose. Only 8% is search-related (which might send referral traffic back) and just 2.2% responds to actual user queries in real time.
This is the core of the robots.txt debate. If 89.4% of AI crawling is taking content to train models, not to serve it back to users who might click through, then the ROI for publishers is structurally negative. The crawl-to-refer ratios confirm this: platforms whose crawling is primarily training-focused (Anthropic, Meta) have the worst ratios. Platforms with significant search components (Perplexity, Google) have better ratios.
The 2.2% "User Action" category is the fastest-growing segment. These are bots like ChatGPT-User that visit pages when a user asks a question. They represent genuine, query-driven traffic that can generate real referrals. According to Cloudflare's own analysis, training now drives nearly 80% of AI bot activity, up from 72% a year ago. But the user-action slice grew 15x year-over-year according to Cloudflare's 2025 Year in Review, and the growth continued into Q1 2026. As AI assistants increasingly browse the web on behalf of users, this category will matter more.
What to do with this insight: Don't treat all AI crawlers as equal. Block training-focused bots (GPTBot, ClaudeBot, Meta-ExternalAgent, CCBot) while explicitly allowing search and user-action bots (OAI-SearchBot, ChatGPT-User, PerplexityBot). You'll block 89.4% of the extractive traffic while preserving the 10.2% that could send actual visitors.
Which industries absorb the most AI crawling?
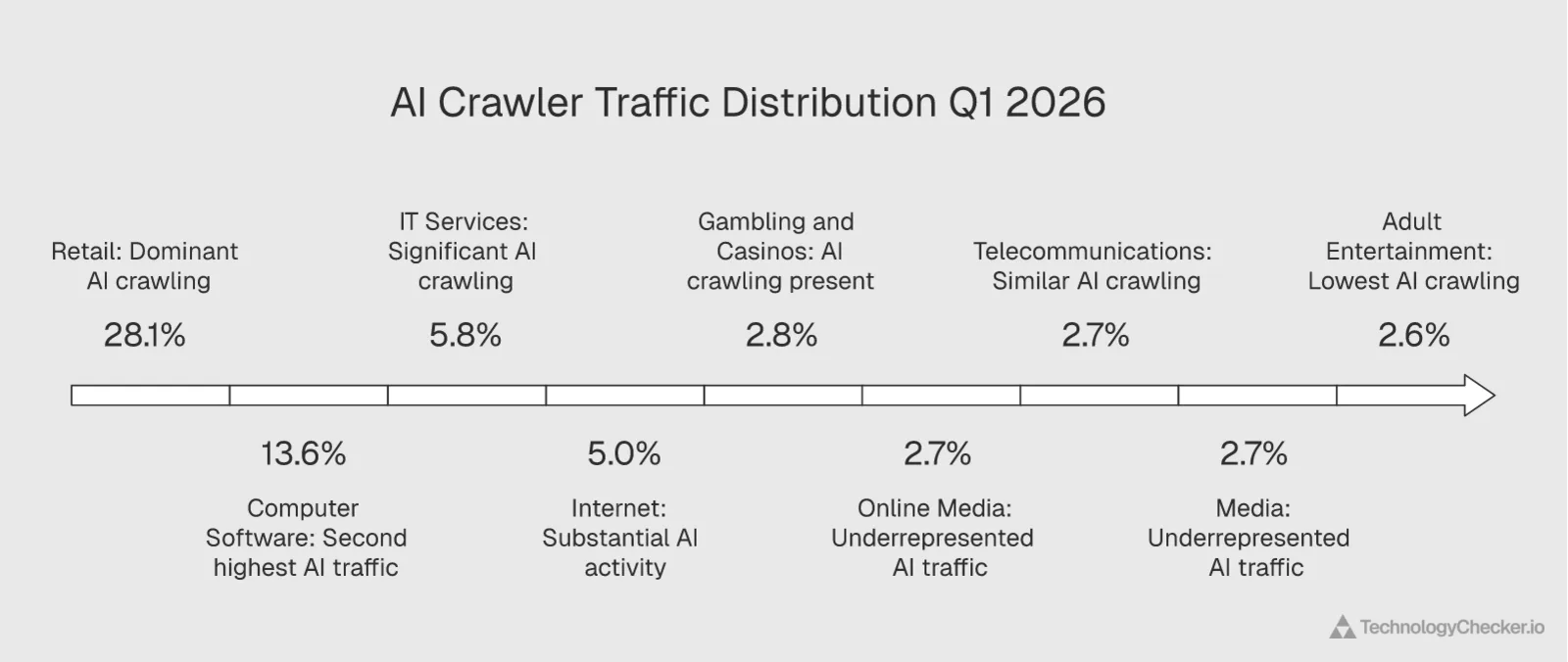
AI crawlers don't hit all industries equally. Here's where they spend their bandwidth:
| Industry | AI Crawler Traffic Share | All Crawler Traffic Share | AI Overweight? |
|---|---|---|---|
| Retail | 28.1% | 20.8% | Yes — disproportionately targeted |
| Computer Software | 13.6% | 17.3% | No — slightly under |
| IT Services | 5.8% | 5.5% | Neutral |
| Internet | 5.0% | 4.9% | Neutral |
| Gambling & Casinos | 2.8% | 6.5% | No — less AI crawling than average |
| Online Media | 2.7% | — | — |
| Telecommunications | 2.7% | 3.1% | Neutral |
| Media | 2.7% | 5.1% | No — less AI crawling than average |
| Marketing & Advertising | — | 6.4% | No — less AI crawling |
| Adult Entertainment | 2.6% | 4.0% | No — less AI crawling |
May 2026 update — Retail's lead held, the long tail grew: By industry, Retail was 28.71% (essentially flat), Computer Software recovered to 13.44%, and Internet rose to 5.41%. On the June 1 robots.txt sample the most-blocked domain categories were Technology 889 domains, Business 782, Ecommerce 289 — a touch below April's counts on a slightly smaller 4,072-file sample, so read this as steady blocking, not a reversal. The new monthly vertical breakdown below shows the same concentration from a cleaner angle: Shopping, Internet/Telecom, and Computer/Electronics together absorb about 63% of all AI crawling, every month of 2026.
Retail takes 28.1% of AI crawler traffic, more than double any other industry. Product descriptions, pricing pages, reviews, and comparison content are exactly the kind of structured, factual data that language models consume voraciously. If you run an e-commerce site (like those built on Shopify), AI crawlers are likely your single largest non-human traffic source after Googlebot.
Computer Software at 13.6% makes sense. Documentation, API references, tutorials, and technical content are high-value training material for code-focused AI models.
Media is underrepresented at 2.7%. This is likely because media companies were among the first to aggressively block AI crawlers through robots.txt, and the blocking is working. Their share of AI crawler traffic is lower than their share of all crawler traffic (5.1%), suggesting the blocking is effectively reducing AI-specific crawling. HUMAN Security's data corroborates this pattern, showing that more than 95% of AI-driven traffic in 2025 was concentrated in retail and e-commerce, streaming and media, and travel and hospitality.
The domain category data from robots.txt tells the same story from the other side. Among the 4,047 robots.txt files Cloudflare parsed on March 30, Technology domains (910) and Business domains (798) had the most AI-specific DISALLOW rules. E-commerce (287) came third.
How did AI crawler demand by vertical move month to month in 2026?
The industry table above is a single snapshot. The more useful question for capacity planning is whether the mix moves. We pulled Cloudflare Radar's vertical breakdown — a broader content taxonomy than the industry field, closer to how Google groups sites — for every month of 2026 so far. Here's the share of all AI crawler traffic each vertical absorbed, month by month:
| Vertical | Jan | Feb | Mar | Apr | May | Trend |
|---|---|---|---|---|---|---|
| Shopping & General Merchandise | 31.30% | 30.59% | 31.62% | 31.89% | 31.73% | Flat, dominant |
| Internet and Telecom | 16.52% | 17.00% | 16.78% | 18.21% | 17.05% | Peaked in April |
| Computer and Electronics | 15.08% | 15.11% | 14.62% | 14.22% | 14.73% | Slow erosion |
| News, Media, and Publications | 9.39% | 8.99% | 8.98% | 8.65% | 9.29% | Dipped, rebounded |
| Business and Industry | 5.09% | 5.09% | 4.98% | 4.88% | 4.88% | Gently down |
| Travel and Tourism | 3.74% | 4.07% | 3.98% | 3.84% | 3.99% | Stable |
| Professional Services | 3.60% | 3.37% | 3.32% | 3.15% | 3.21% | Eroding |
| Gambling | 3.01% | 3.13% | 2.84% | 2.32% | 2.29% | Steepest decline |
| Finance | 2.87% | 2.97% | 2.87% | 2.83% | 2.77% | Flat |
Five things stand out across the monthly series.
Shopping never moves, and it never stops leading. Shopping & General Merchandise sat between 30.6% and 31.9% every single month — the most stable line in the dataset. Nearly a third of all AI crawling, all year, targets product pages, pricing, and merchandise catalogs. If you run commerce, AI crawlers are a permanent, roughly fixed fraction of your bot load, not a spike you can wait out.
The top three verticals are about 63% of everything, every month. Shopping, Internet/Telecom, and Computer/Electronics combined ran 62.9% (Jan), 62.7% (Feb), 63.0% (Mar), 64.3% (Apr), and 63.5% (May). AI crawl demand is structurally concentrated in commerce, infrastructure and telecom content, and tech and electronics — and that concentration is itself stable. The remaining six verticals split the other third.
Internet and Telecom is the swing vertical. It was the only big category with real month-to-month range, climbing to an 18.21% peak in April before settling back to 17.05% in May. April's broad AI-crawler surge — the Applebot and early-Bytespider month — landed disproportionately on telecom and infrastructure content before broadening out again.
News and Media dipped through Q1, then rebounded. Publishers block AI crawlers hardest, and the data shows it: News, Media & Publications slid from 9.39% in January to 8.65% in April as blocking bit. The rebound to 9.29% in May tracks the arrival of search-and-user-action bots (Claude-SearchBot, plus rising OAI-SearchBot ALLOW shares) that publishers are more willing to admit. The crawl returning to media is the referral-capable kind, not the training kind.
Gambling is the clearest faller. It dropped from 3.01% in January to 2.29% in May, the steepest decline of any vertical — a 0.72-point fall, about 24% of its share gone in five months. Professional Services eroded on a similar slope. Both are categories where the high-value content increasingly sits behind logins or paywalls that crawlers can't reach, so the AI share migrates to verticals that publish openly.
What to do with this: forecast AI crawler load by vertical, not as a single number. A commerce site should plan for roughly 31% of AI crawl traffic to be the durable Shopping baseline that won't recede. A media site should expect training-bot crawling to keep falling as blocking works, while search-bot crawling slowly returns. And because the top three verticals barely move, you can size capacity off a single quarter of data and trust it — the mix doesn't lurch month to month.
Is AI crawler blocking increasing?
Yes. We tracked the weekly share of DISALLOW rules for each AI crawler across the full 13 weeks of Q1 2026:
| AI Crawler | Jan 5 Share | Mar 30 Share | Q1 Change | Trend |
|---|---|---|---|---|
| GPTBot | 11.93% | 11.75% | -0.18pp | Flat (already peak) |
| CCBot | 10.59% | 10.41% | -0.18pp | Flat |
| ClaudeBot | 9.58% | 10.09% | +0.51pp | Growing fastest |
| Google-Extended | 8.82% | 9.22% | +0.40pp | Growing |
| Bytespider | 8.45% | 8.58% | +0.13pp | Flat |
| meta-externalagent | 6.93% | 7.44% | +0.51pp | Growing fastest |
| Amazonbot | 6.44% | 7.31% | +0.87pp | Growing fastest |
| Googlebot | 8.09% | 7.69% | -0.40pp | Declining |
| Applebot-Extended | 6.53% | 6.92% | +0.39pp | Growing |
May 2026 update — the April crossovers reverted: May's fully-blocked DISALLOW shares across the AI category: GPTBot 4.71%, CCBot 4.28%, ClaudeBot 4.18%, Google-Extended 3.82%, Bytespider 3.70%, Amazonbot 3.23%, Meta-ExternalAgent 3.22%, Applebot-Extended 2.98%, Googlebot 2.77%. Two reversals from April: Google-Extended moved back ahead of Bytespider (April had Bytespider ahead), and CCBot edged back ahead of ClaudeBot by raw mention count (463 vs 457 on June 1). Every top bot's share eased because the "other" bucket — the long tail of named AI user-agents — grew to 67% of AI DISALLOW mentions. Site owners are blocking more distinct bots, which dilutes each leader's share even as total blocking holds. The order at the top is a coin flip now; the magnitudes are what's stable.
Three trends are clear:
GPTBot blocking has plateaued. It was already the most blocked bot at the start of Q1 and stayed flat throughout. Most sites that intend to block GPTBot have already done so. According to a Search Engine Journal report on a Hostinger study, GPTBot's website coverage dropped from 84% to 12% over their study period, while OAI-SearchBot reached 55.67% average coverage. That gap tells you everything: sites are surgically blocking the training bot while welcoming the search bot.
ClaudeBot and meta-externalagent are catching up fast. Both gained +0.51 percentage points in Q1, the joint-fastest growth in DISALLOW rules. ClaudeBot's growth correlates directly with awareness of its terrible crawl-to-refer ratio. As more SEO professionals and publishers discover the 20,583:1 number, blocking will likely continue to accelerate.
Amazonbot blocking grew the most at +0.87pp. Amazonbot isn't typically discussed alongside GPTBot and ClaudeBot in the AI crawler conversation, but the data shows website owners are increasingly blocking it. This may reflect concerns about Amazon using crawled data to compete with the very retailers it crawls.
Googlebot blocking is declining. This is the only major crawler seeing reduced blocking, likely because website owners are learning to use the Google-Extended user agent to block Google's AI training specifically while keeping search indexing intact. They're switching from blunt Googlebot blocks to targeted Google-Extended blocks.
External context: An academic study published on arXiv found that AI-blocking by reputable sites increased from 23% in September 2023 to nearly 60% by May 2025, with reputable sites forbidding an average of 15.5 AI user agents. Meanwhile, misinformation sites prohibit fewer than one. The trend we're measuring in Q1 2026 is a continuation of this multi-year acceleration.
Which AI crawlers are explicitly welcomed?
The robots.txt story isn't only about blocking. Some AI crawlers are actively welcomed through explicit ALLOW rules:
| AI Crawler | ALLOW Share | DISALLOW Share | Net Direction |
|---|---|---|---|
| PerplexityBot | 5.16% | — | Strongly welcomed |
| ChatGPT-User | 4.76% | — | Strongly welcomed |
| OAI-SearchBot | 4.22% | — | Strongly welcomed |
| GPTBot | 5.65% | 5.52% | Split — some allow, some block |
| ClaudeBot | 4.24% | 4.88% | Slightly more blocked |
| Google-Extended | 4.29% | 4.44% | Slightly more blocked |
May 2026 update — the welcomed-bot trio kept rising, and GPTBot tipped net-positive: May ALLOW shares: PerplexityBot 5.48%, ChatGPT-User 4.96%, OAI-SearchBot 4.44%, GPTBot 5.84%, Google-Extended 4.84%, ClaudeBot 4.63%. All three search/user-action bots gained share again. The notable shift: GPTBot's ALLOW share (5.84%) now sits above its DISALLOW share (4.71%) for the first time in our tracking — the web is leaning slightly toward allowing OpenAI's crawler. The "block training, allow search" posture is now the visible consensus, not just our recommendation. One caveat: Anthropic's new Claude-SearchBot is too recent to show meaningful ALLOW adoption yet. robots.txt rules lag bot launches by months, which is exactly the gap this report keeps flagging.
PerplexityBot, ChatGPT-User, and OAI-SearchBot are net positive. They appear in ALLOW rules without significant DISALLOW presence. All three have something in common: they're search or user-action bots that send referral traffic back to publishers. The robots.txt data confirms what the crawl-to-refer ratios suggest, sites are willing to give access to bots that return traffic.
GPTBot is genuinely split. Nearly identical ALLOW and DISALLOW percentages mean the internet is divided on OpenAI's training crawler. This probably reflects the messy reality that GPTBot serves dual purposes, and different sites weigh those purposes differently.
This is where sophisticated operators are getting granular. Instead of a blanket block on all OpenAI crawlers, they're writing robots.txt rules that block GPTBot (training) while explicitly allowing OAI-SearchBot (search) and ChatGPT-User (user action). That's the data-informed approach.
The complete list of known AI crawler user-agent strings

One of the biggest challenges in managing robots.txt AI crawlers is simply knowing which user-agent strings to target. AI companies don't always publicize their bots, and new ones appear regularly.
Here's the most current list of AI crawler user-agent strings, compiled from our crawling infrastructure's observations, Cloudflare Radar data, and the community-maintained ai-robots-txt GitHub repository:
Training crawlers (high crawl, low/zero referrals)
| User-Agent | Operator | Purpose |
|---|---|---|
| GPTBot | OpenAI | Model training data |
| ClaudeBot | Anthropic | Model training data |
| Claude-Web | Anthropic | Model training data |
| Meta-ExternalAgent | Meta | AI training (zero referrals) |
| CCBot | Common Crawl | Open dataset for AI training |
| Google-Extended | Gemini / AI training | |
| Bytespider | ByteDance | AI training + TikTok |
| Amazonbot | Amazon | Alexa + AI features |
| Applebot-Extended | Apple | Apple Intelligence training |
| Diffbot | Diffbot | Web data extraction |
| FacebookBot | Meta | AI training |
| Omgilibot | Webz.io | Data mining |
| cohere-ai | Cohere | Model training |
| AI2Bot | Allen AI | Research model training |
| Kangaroo Bot | Kangaroo LLM | Model training |
| Timpibot | Timpi | Decentralized search training |
| VelenPublicWebCrawler | Velen | Model training |
| Webzio-Extended | Webz.io | Extended data collection |
| iaskspider | iAsk.ai | AI training |
Search and user-action crawlers (send referral traffic)
| User-Agent | Operator | Purpose |
|---|---|---|
| OAI-SearchBot | OpenAI | ChatGPT search results |
| ChatGPT-User | OpenAI | Real-time user queries |
| Claude-SearchBot | Anthropic | Claude web search results (new in 2026) |
| PerplexityBot | Perplexity | AI search engine |
| Bingbot | Microsoft | Search + Copilot |
| Googlebot | Search indexing | |
| YouBot | You.com | AI search |
This distinction matters. We've seen site owners paste a "block all AI crawlers" snippet into their robots.txt without realizing they're also blocking the search bots that actually send visitors. Use the training vs. search categorization above to make targeted decisions.
Common mistakes with AI crawler directives

After scanning millions of robots.txt files through our technology detection pipeline, I've seen the same mistakes repeatedly. Here are the five most common, with fixes.
Mistake 1: Blocking all OpenAI bots instead of just the training bot
# Wrong — blocks search referrals too
User-agent: GPTBot
Disallow: /
User-agent: OAI-SearchBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
# Right — blocks training, allows search
User-agent: GPTBot
Disallow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
OpenAI operates three distinct user-agent strings. GPTBot handles training data collection. OAI-SearchBot powers ChatGPT search results and actually sends referral traffic back. ChatGPT-User fetches pages in real time when users ask questions. Blocking all three costs you search visibility with zero upside. According to a Reuters Institute study, 48% of the most widely used news websites across ten countries block OpenAI's crawlers, but many don't differentiate between the training and search bots.
Mistake 2: Placing AI bot rules after a wildcard disallow
# Wrong — wildcard catches everything first
User-agent: *
Disallow: /private/
User-agent: GPTBot
Disallow: /
Some robots.txt parsers process rules differently. The spec says the most specific user-agent match wins, but not all crawlers follow the spec perfectly. Always test your configuration with Google's robots.txt tester to verify your rules work as intended.
Mistake 3: Forgetting that robots.txt is case-sensitive for paths
The user-agent field is case-insensitive, but paths in Disallow and Allow directives are case-sensitive. Disallow: /Blog/ won't block access to /blog/. Double-check your actual URL paths.
Mistake 4: Assuming robots.txt blocks indexing
robots.txt blocks crawling, not indexing. If other sites link to your pages, search engines can still index the URLs without crawling the content. If you need to prevent indexing entirely, use a noindex meta tag or X-Robots-Tag HTTP header instead.
Mistake 5: Not updating rules as new AI bots appear
AI companies launch new crawlers regularly. A robots.txt written in 2024 that blocks GPTBot and ClaudeBot misses meta-externalagent, Bytespider, Amazonbot, Applebot-Extended, and dozens of others. Review your robots.txt quarterly. The ai-robots-txt GitHub repository is a good reference for staying current.
robots.txt limitations: when to use firewall rules instead
Here's something most guides won't tell you plainly: robots.txt is voluntary. It's a set of suggestions, not a technical barrier. Any crawler can read your robots.txt and choose to ignore it completely.
According to a UC San Diego research paper, 77% of participants surveyed had never even heard of robots.txt. And among AI companies, compliance with robots.txt varies. Multiple reports have documented AI crawlers accessing content that robots.txt explicitly blocks.
This means robots.txt should be your first line of defense but not your only one. Here's how the options compare:
| Method | Blocks Compliant Bots | Blocks Non-Compliant Bots | Implementation Difficulty | Risk |
|---|---|---|---|---|
| robots.txt | Yes | No | Low (text file) | None |
| Cloudflare WAF rules | Yes | Yes | Medium | May block legitimate users if misconfigured |
| Rate limiting | Partial | Yes | Medium | May affect site performance |
| User-agent blocking (server-side) | Yes | Yes (if detected) | Medium-High | Spoofed user agents bypass it |
| Bot management solutions | Yes | Yes | High (cost + setup) | Most effective but expensive |
When robots.txt is enough
- You're blocking well-known, compliant bots (GPTBot, ClaudeBot, Googlebot)
- Your goal is to communicate policy, not enforce it technically
- You want to control search engine AI training without losing search indexing
When you need firewall rules
- You've identified bots ignoring your robots.txt
- Your server costs are spiking from aggressive crawling
- You need to protect high-value content (pricing pages, proprietary data)
- You're dealing with bots that disguise their user-agent strings
Cloudflare Turnstile and similar tools add a verification layer that bots can't bypass by simply ignoring robots.txt. For most mid-market sites, the combination of robots.txt for policy signaling and a WAF for enforcement gives you the best coverage.
llms.txt vs robots.txt: a new standard for AI-specific instructions

While robots.txt was designed for search engine crawlers in the 1990s, a new file called llms.txt has emerged specifically for communicating with large language models. It's worth understanding the difference and when you might use both.
robots.txt uses the Robots Exclusion Protocol to tell crawlers which URLs they can access. It was built for search engines that crawl, index, and link back to your content. The format is technical: User-agent strings, Allow/Disallow directives, Sitemap references.
llms.txt is a proposed convention for providing AI-readable information about your site. Instead of restricting access, it describes your content in a structured way that LLMs can use. Think of it as a site map written for AI understanding rather than search engine indexing.
| Feature | robots.txt | llms.txt |
|---|---|---|
| Purpose | Control crawl access | Describe site content for AI |
| Format | User-agent + Disallow/Allow | Markdown-like, human readable |
| Enforceability | Voluntary (standard since 1994) | Voluntary (emerging, no standard body) |
| AI training control | Yes (via specific user agents) | No (descriptive, not restrictive) |
| Search impact | Direct (blocks crawling) | None (informational only) |
| Adoption | Widespread | Early stage |
Here's the practical takeaway: robots.txt and llms.txt serve different functions. robots.txt controls access. llms.txt describes content. If your priority is blocking AI training crawlers, robots.txt is still the tool. If you want to help AI systems understand your site structure and cite you accurately, llms.txt adds value on top.
We're monitoring llms.txt adoption across our domain dataset (29.9 million currently active) and will publish adoption numbers once the sample is statistically meaningful. For now, focus your energy on getting robots.txt right since it has direct, measurable impact today.
A data-driven framework for robots.txt decisions
Based on everything we've analyzed, here's a decision framework for every major AI crawler:
| Crawler | Recommendation | Rationale |
|---|---|---|
| GPTBot (OpenAI) | Block unless you want ChatGPT training visibility | 1,255:1 ratio. Block GPTBot, allow OAI-SearchBot separately. |
| ClaudeBot (Anthropic) | Block, but allow Claude-SearchBot separately | 20,583:1 ratio for training. As of May 2026 Anthropic also runs Claude-SearchBot, which returns traffic. |
| Claude-SearchBot (Anthropic) | Allow | New in 2026 — Anthropic's search crawler. Returns referral traffic, like OAI-SearchBot. |
| Meta-ExternalAgent (Meta) | Block | Zero referrals. Pure training extraction. |
| Bytespider (ByteDance) | Block | Now the #4 AI crawler (10.25% in May 2026) and crawls straight through blocks. Training-focused, low referral return. |
| CCBot (Common Crawl) | Block unless you value open datasets | Used by many AI companies indirectly. |
| Google-Extended | Block | Blocks Google's AI training while keeping search indexing. Best of both worlds. |
| OAI-SearchBot (OpenAI) | Allow | Handles ChatGPT search — sends referral traffic. |
| ChatGPT-User (OpenAI) | Allow | User-action bot — responds to real queries. |
| PerplexityBot (Perplexity) | Allow | 111:1 ratio — best among dedicated AI companies. |
| Bingbot (Microsoft) | Allow | 32:1 ratio. Search indexing + Copilot. Acceptable trade-off. |
| Googlebot | Always allow | 5:1 ratio. Blocking means search invisibility. |
Here's what a data-informed robots.txt looks like in practice:
# Block AI training crawlers (high crawl-to-refer ratio)
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: cohere-ai
Disallow: /
User-agent: Diffbot
Disallow: /
User-agent: Omgilibot
Disallow: /
User-agent: FacebookBot
Disallow: /
# Allow AI search and user-action bots (send referral traffic)
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
# Always allow search engines
User-agent: Googlebot
Allow: /
User-agent: bingbot
Allow: /
This approach blocks the vast majority of training crawling while preserving the bots that could send actual referral traffic back to your site.
2026 AI crawler benchmarks at a glance
Here are the key benchmarks, consolidated for quick reference (Q1 2026 baseline, with May 2026 values where they've moved):
| Benchmark | Value | Source | Notes |
|---|---|---|---|
| Most blocked AI crawler | GPTBot (4.71% of DISALLOW rules, May 2026) | Our Cloudflare Radar analysis | Followed by CCBot (4.28%) |
| Fastest-rising AI crawler (traffic) | Bytespider — 3.5% → 10.25% (Q1 → May 2026) | Our Cloudflare Radar analysis | Nearly tripled; now the #4 AI crawler |
| Top AI-crawled vertical | Shopping & General Merchandise — ~31% every month | Our Cloudflare Radar analysis | Stable Jan–May 2026 |
| Worst crawl-to-refer ratio | Anthropic — 20,583:1 | Our Cloudflare Radar analysis | 4,117x worse than Google |
| Best AI-company crawl ratio | Perplexity — 111:1 | Our Cloudflare Radar analysis | Search model returns traffic |
| Training + mixed traffic share | 87.5% of AI crawling (May 2026) | Our Cloudflare Radar analysis | Search/user-action rose to 11.9% |
| Bot traffic as % of all web | 30.6% | Our Cloudflare Radar analysis | AI crawlers are a growing share |
| AI traffic growth (2025 YoY) | 187% | HUMAN Security report | Agentic AI traffic up 7,851% |
| Top news sites blocking AI bots | 79% | BuzzStream study | 14% block all bots, 18% block none |
| Retail share of AI crawling | 28.7% (May 2026) | Our Cloudflare Radar analysis | More than double any other industry |
| New entrant | Claude-SearchBot — 2.22% (May 2026) | Our Cloudflare Radar analysis | Anthropic's first dedicated search crawler |
| GPTBot website coverage decline | 84% down to 12% | Search Engine Journal / Hostinger | OAI-SearchBot reached 55.67% |
What this means for technology intelligence

The robots.txt arms race creates a growing problem for any data product that relies on web crawling. As more sites block more bots, crawling-dependent tools develop blind spots.
At TechnologyChecker, we've been dealing with this reality since day one. Our technology detection pipeline uses multi-signal detection specifically because we knew crawling access would tighten:
- DNS record analysis — Certificate Authority data reveals cloud providers (we tracked 10.9 billion certificates in Q1 2026), CNAME records reveal CDN and hosting infrastructure, MX records reveal email providers
- HTTP header fingerprinting — Server headers, X-Powered-By headers, and security headers reveal backend technologies without needing to render page content
- JavaScript signature detection — Library fingerprints in public assets identify frontend frameworks
- Historical baseline data — 20 years of technology adoption patterns let us detect changes even when current access is restricted
The robots.txt data we've analyzed in this report quantifies what we've observed operationally: the open web is closing. The 13.8% of sites that already block GPTBot will likely double within a year. Crawl-to-refer ratios will be the metric that determines whether a bot gets access or gets blocked.
Technology intelligence tools that depend on a single data collection method, whether that's crawling, browser extensions, or job posting analysis, will face increasing gaps. The sites that are blocking most aggressively (Technology at 910 DISALLOW rules, Business at 798) are exactly the sites that B2B sales teams need intelligence on. That makes multi-signal detection not just a nice-to-have but a requirement for accurate technographic data.
Frequently Asked Questions
Is there a robots.txt for AI?
Yes. The standard robots.txt file is the primary mechanism for controlling AI crawler access. You specify AI-specific user-agent strings (GPTBot, ClaudeBot, Meta-ExternalAgent, etc.) with Disallow directives. There's also an emerging llms.txt standard designed specifically for communicating with large language models, but it's descriptive rather than restrictive. For blocking AI training crawlers, robots.txt remains the established and widely supported approach.
Is robots.txt a legal thing?
robots.txt itself isn't a law. It's a technical protocol, a set of instructions that well-behaved crawlers follow voluntarily. However, courts have considered robots.txt as evidence of a website's expressed wishes regarding access. In several legal disputes involving web scraping, including cases against AI companies, robots.txt policies have been cited as proof that content was accessed against the site owner's stated terms. It's a policy signal, not a legal contract, but it carries weight in court.
Is robots.txt a vulnerability?
Not a security vulnerability in the traditional sense, but it can expose information. robots.txt files are publicly readable, and Disallow paths can reveal the existence of directories or files you might not want exposed (like /admin/, /staging/, or /internal-api/). Never rely on robots.txt as a security measure. Use proper authentication, access controls, and server-side rules to protect sensitive content. robots.txt is for managing crawler behavior, not securing your site.
How do you block AI crawlers in robots.txt in 2026?
Add specific User-agent and Disallow directives for each AI crawler you want to block. In 2026, you need to target at least 10-15 user-agent strings to cover the major AI crawlers. We recommend using the data-driven framework in this article: block training bots (GPTBot, ClaudeBot, Meta-ExternalAgent, CCBot, Bytespider, Google-Extended, Amazonbot) while allowing search bots that return traffic (OAI-SearchBot, ChatGPT-User, PerplexityBot). The full robots.txt code example earlier in this post is ready to copy and deploy.
Should I allow or block GPTBot and ClaudeBot?
The data suggests blocking both training crawlers for most websites. GPTBot has a 1,255:1 crawl-to-refer ratio, meaning it crawls 1,255 pages for every referral it sends back. ClaudeBot is far worse at 20,583:1 (a Q1 2026 figure). By the Q2 2026 close both had improved, GPTBot to 870:1 and ClaudeBot to 5,143:1, but ClaudeBot remained the most extractive major crawler by roughly 1,000x versus Google's 5:1, so the recommendation holds. If you block GPTBot, separately allow OAI-SearchBot, which handles ChatGPT search and actually sends referral traffic (it appeared in 4.44% of ALLOW rules in our May 2026 data). The same logic now applies to Anthropic: as of May 2026 Anthropic runs Claude-SearchBot (2.22% of AI crawler traffic), a dedicated search crawler that returns traffic — so block ClaudeBot (training) while allowing Claude-SearchBot (search). That's a change from our earlier guidance, which assumed Anthropic had no search-specific bot. The one exception: if you specifically want your content used in ChatGPT or Claude training, allowing the training crawlers is the trade-off.
Did AI crawlers get less extractive in 2026?
The worst ones did, sharply. Over the year to the Q2 2026 close, Anthropic's crawl-to-refer ratio (pages crawled per referral returned) collapsed from 91,702:1 to 5,143:1, roughly an 18x improvement, and OpenAI's fell from 1,257:1 to 870:1. But the trend cut both ways: several crawlers that used to sit near a healthy 1:1 got more extractive, with ByteDance moving from 1.8:1 to 9.1:1 and Mistral from 1.6:1 to 63:1. The field converged toward the middle, and the gap between the most and least extractive crawler compressed from about 340,000:1 to roughly 3,000:1. Anthropic is still the most extractive of the major bots, so it stays on the block list, but the direction of travel is toward less extraction, not more.
What percentage of AI crawler requests get blocked in 2026?
For AI crawlers specifically, about 12.85% of requests returned a 4xx client error in Q2 2026, up from 7.53% a year earlier. The clearest deliberate-block signal, the 403 Forbidden rate, more than doubled year over year, from 3.63% to 8.56%. Important context: across all crawlers Cloudflare tracks (including scrapers, SEO tools, and vulnerability scanners), the 4xx rate is far higher at 35.8%. Named AI crawlers are blocked less than the general bot population because they mostly request real, existing URLs. So blocking of AI crawlers is real and accelerating, but they are not yet blocked as hard as the internet's broader bot noise.
Which AI crawler is blocked most in robots.txt in 2026?
GPTBot, and it has held that position since Q1 2026. On the Q2 close snapshot (June 29, 2026), the most-named AI user-agents in parsed robots.txt files were GPTBot (690 mentions), ClaudeBot (594), Google-Extended (558), CCBot (554), and Bytespider (467). The cluster behind GPTBot trades places month to month, so treat the exact rank order below the leader as noise. What is stable is the direction: site owners keep naming more distinct AI user-agents in more files, and Technology, Business, and Ecommerce domains publish the most AI-targeting rules.
Our Methodology
This analysis uses data from multiple Cloudflare Radar API endpoints, which aggregate traffic patterns across Cloudflare's global network spanning 330 cities in 125+ countries. Cloudflare processes over 81 million HTTP requests per second and 67 million DNS queries per second, providing one of the most extensive views of global internet activity available.
Data period: January 1 through March 31, 2026 (Q1 2026 baseline), with full-month refreshes for April and May 2026, and a full-quarter Q2 2026 close (April 1 through June 30) with a year-over-year layer against Q2 2025 (April 1 through June 30, 2025). The monthly vertical breakdown covers January through May 2026. Most recent re-pull: July 2, 2026.
Geographic scope: Global
Endpoints used:
- robots.txt analysis (
get_robots_txt_data) — DISALLOW and ALLOW directive distributions by user agent, domain category breakdowns, weekly timeseries trends. Sample: 4,047 robots.txt files parsed on March 30, 2026. - Crawl-to-refer ratios (
get_bots_crawlers_data) — Ratio of crawl requests to referral traffic by bot operator, with daily timeseries. - AI bot traffic (
get_ai_data) — Traffic share by user agent, crawl purpose classification, and both the industry and vertical targeting dimensions. The monthly vertical table pulls thebots/summary/verticaldimension separately for each calendar month of 2026 so each row is a clean full-month snapshot rather than a smoothed timeseries. - HTTP traffic (
get_http_data) — Human vs bot traffic split.
June 2026 refresh: On June 1, 2026 we re-pulled every metric in this report for the full month of May 2026 (May 1–31) and added the month-by-month vertical series for January through May. The headline changes from the April update: Bytespider nearly doubled to 10.25% of AI crawler traffic (now the #4 crawler), GPTBot rebounded to reclaim #3, Applebot's April surge half-reversed, Anthropic's new Claude-SearchBot appeared at 2.22%, and the search/user-action share broke above its long-standing ~10% ceiling to 11.91%. Where May reversed an April call, we've said so in the text rather than quietly overwriting the earlier read.
July 2026 refresh (Q2 close and first year-over-year layer): On July 2, 2026 we added the full calendar-quarter Q2 2026 close (April 1 through June 30) and, for the first time, pulled the same window one year earlier (Q2 2025) for a like-for-like year-over-year comparison, plus Q1 2026 for quarter-over-quarter momentum. The year-over-year metrics come from the AI-bot traffic datasets, which accept historical windows: bots/crawlers/summary/crawl_refer_ratio (the crawl-to-refer ratios), ai/bots/summary/{user_agent, crawl_purpose, response_status, industry, vertical}, and http/summary/bot_class. Two data-honesty notes. First, the robots.txt directive rankings (robots_txt/top/{user_agents/directive, domain_categories}) are the one dataset Cloudflare returns as a rolling single-day snapshot rather than a windowed aggregate, so those figures are reported at the Q2 close (snapshot dated June 29, 2026) with no year-over-year comparison, and the "are sites fighting back?" question is answered instead by the enforced 403 rate, which is windowed. Second, the 4xx block rate in this report's Q2 section (about 12.85% for AI bots specifically, via ai/bots/summary/response_status) is deliberately narrower than the 35.8% all-crawler figure in our AI adoption report (via bots/crawlers/summary/response_status_category), because the latter includes scrapers and scanners that AI-named crawlers are not; we cite both and label which population each measures. The Q1 crawl-to-refer pull reproduced this report's originally published Q1 table exactly, confirming the method. Where the Q2 close reverses or extends an earlier monthly read, we say so in the new section rather than overwriting the layers below.
Limitations: robots.txt percentages represent the share of directives across Cloudflare's monitored domains, not absolute blocking rates across all internet domains. Crawl-to-refer ratios can vary significantly day-to-day, and daily extremes (such as Anthropic's spikes above 100,000:1) may reflect transient crawl bursts rather than sustained behavior. Some AI crawlers may not identify themselves accurately in user agent strings, which means true crawl volumes could be higher. This analysis also doesn't account for sites using server-side blocking or WAF rules that never appear in robots.txt.
We plan to update this analysis quarterly. If you'd like to see how AI crawler blocking affects technology detection accuracy across your target accounts, explore our platform rankings data or check how cloud provider traffic share interacts with bot management at the infrastructure level.
Data source: Cloudflare Radar API (radar.cloudflare.com) Analysis and insights by TechnologyChecker.io
David Thomson
CTO

